Batch Normalization
Batch Normalization 的优点
- 考虑一个网络计算:
学习 的过程可以被视为使用 作为子网络的输入,例如在SGD的一步中,
等价于一个独立的只含有一层($F_2$ 层)的网络对于输入 的更新。因此,对于每一层网络 的分布随时间保持固定是有利的。 这样, 不必重新调整以补偿 分布的变化。
使用 Batch Normalization 可以防止非线性层产生 “饱和” 现象(进一步导致梯度消失)
例如:sigmoid 函数 其导数在 很大的时候对于 的导数值很小(饱和状态),梯度将难以传导到之前到 layers,如果我们确保在网络训练时非线性输入的分布更稳定,则优化器将不太可能陷入饱和状态,训练过程会加速。
Batch Normalization 本身有在训练过程中增加随机性,在测试过程中消除随机性的功能(训练过程中使用batch 的数据特征,测试时使用训练过程中采用 running average 得到的数据特征。)具有防止过拟合的效果。一定程度上可以减少对于 dropout 的使用。
- 实际使用中,可根据具体情况决定 BN dropout 的使用,先尝试仅使用 BN 然后如果仍有严重过拟合,再结合使用 dropout 层。
Batch Normalization
Normalization via Mini-batch Statistics
For a layer with d-dimensional input , we will normalize each dimension
where the expectation and variance are computed over the training data set. As shown in (LeCun et al., 1998b), such normalization speeds up convergence, even when the features are not decorrelated.
同时,考虑到直接使用上述操作可能降低模型表述能力,有些模型的层需要学习到不同的分布。为解决此问题, 我们需要插入网络的 BN 变换可以成为恒等变换(输入等于输出)。为此对于每个激活 引入参数 对直接normalization的结果进行变换:
网路通过学习参数 动态调整所需要的 normalization。极端情况下 BN 层可能学到恒等变换。
BN 层的前向传播算法

我们用 表示 是模型中可学习的参数。注意到 不仅仅受到输入 的影响也受到
mini-batch 中其他 的影响。我们可以将 BN 层视为将每一个标准化的 输入到一个 的子网络中。
BN 层 的反向传播算法
To derive the backward pass you should write out the computation graph for batch normalization and backprop through each of the intermediate nodes. Some intermediates may have multiple outgoing branches; make sure to sum gradients across these branches in the backward pass.
为了使得反向传播算法中的计算更加清晰,我们将从 $\hat{x_i}$ 生成 $y$ 的过程以矩阵的形式表示如下:
根据公式(5) 以及正向传播计算方法,我们可以得到如下反向传播计算公式:
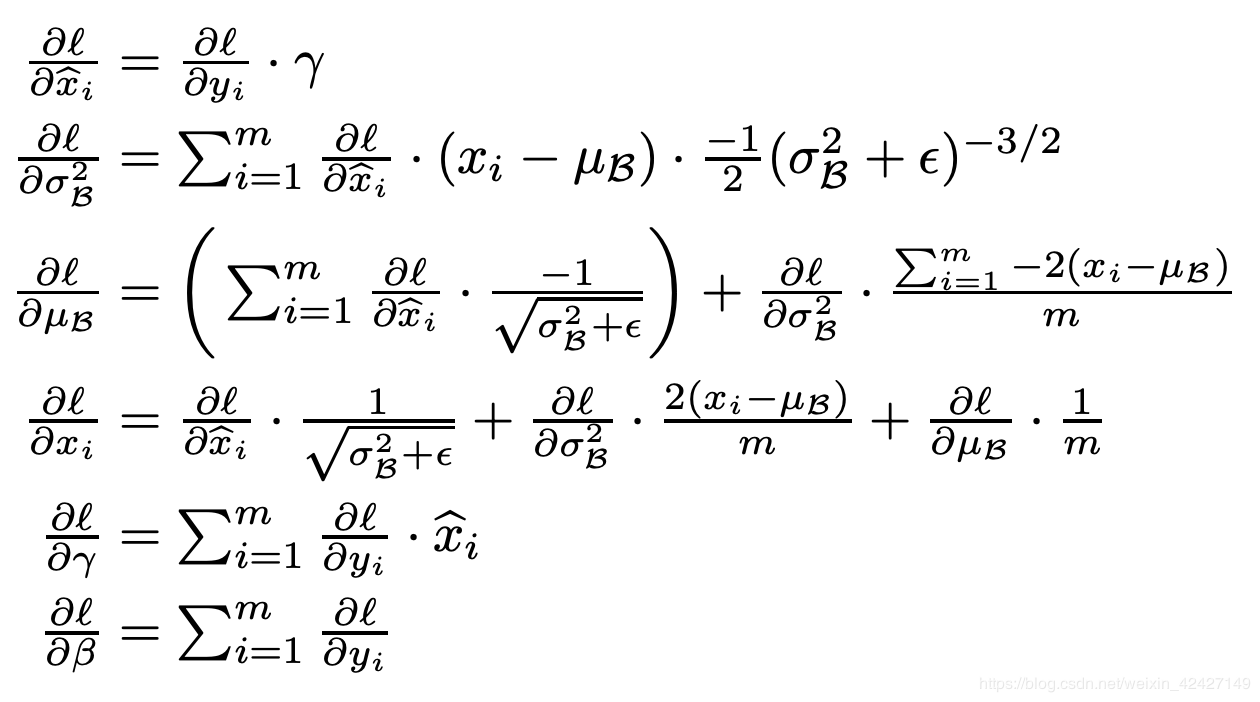
Implement From Scratch
- 正向传播过程:
def batchnorm_forward(x, gamma, beta, bn_param):
"""
Forward pass for batch normalization.
During training the sample mean and (uncorrected) sample variance are
computed from minibatch statistics and used to normalize the incoming data.
During training we also keep an exponentially decaying running mean of the
mean and variance of each feature, and these averages are used to normalize
data at test-time.
At each timestep we update the running averages for mean and variance using
an exponential decay based on the momentum parameter:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
Note that the batch normalization paper suggests a different test-time
behavior: they compute sample mean and variance for each feature using a
large number of training images rather than using a running average. For
this implementation we have chosen to use running averages instead since
they do not require an additional estimation step; the torch7
implementation of batch normalization also uses running averages.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))
out, cache = None, None
if mode == 'train':
#######################################################################
# TODO: Implement the training-time forward pass for batch norm. #
# Use minibatch statistics to compute the mean and variance, use #
# these statistics to normalize the incoming data, and scale and #
# shift the normalized data using gamma and beta. #
# #
# You should store the output in the variable out. Any intermediates #
# that you need for the backward pass should be stored in the cache #
# variable. #
# #
# You should also use your computed sample mean and variance together #
# with the momentum variable to update the running mean and running #
# variance, storing your result in the running_mean and running_var #
# variables. #
# #
# Note that though you should be keeping track of the running #
# variance, you should normalize the data based on the standard #
# deviation (square root of variance) instead! #
# Referencing the original paper (https://arxiv.org/abs/1502.03167) #
# might prove to be helpful. #
#######################################################################
batch_mean = np.mean(x, axis=0, keepdims=True)
batch_var = np.var(x, axis=0, keepdims=True)
x_hat = (x - batch_mean) / np.sqrt(batch_var + eps)
out = gamma * x_hat + beta
cache = (x, gamma, beta, x_hat, batch_mean, batch_var, eps)
running_mean = momentum * running_mean + (1-momentum) * batch_mean
running_var = momentum * running_var + (1-momentum) * batch_var
elif mode == 'test':
#######################################################################
# TODO: Implement the test-time forward pass for batch normalization. #
# Use the running mean and variance to normalize the incoming data, #
# then scale and shift the normalized data using gamma and beta. #
# Store the result in the out variable. #
#######################################################################
x_hat = (x - running_mean) / np.sqrt(running_var + eps)
out = gamma * x_hat + beta
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return out, cach
- 反向传播过程:
def batchnorm_backward(dout, cache):
"""
Backward pass for batch normalization.
For this implementation, you should write out a computation graph for
batch normalization on paper and propagate gradients backward through
intermediate nodes.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for batch normalization. Store the #
# results in the dx, dgamma, and dbeta variables. #
# Referencing the original paper (https://arxiv.org/abs/1502.03167) #
# might prove to be helpful. #
###########################################################################
x, gamma, beta, x_hat, batch_mean, batch_var, eps = cache
num_sample = x.shape[0]
dhat_x = dout * gamma
dvar = np.sum(dhat_x * (x - batch_mean), axis=0) * (-1/2) * (batch_var+eps) ** (-3/2)
dmean = np.sum(dhat_x * (-1/np.sqrt(batch_var + eps)), axis=0) + dvar * np.sum(x - batch_mean, axis=0) * (-2 / num_sample)
dx = dhat_x / np.sqrt(batch_var + eps) + dvar * 2 / num_sample * (x - batch_mean) + dmean / num_sample
dgamma = np.sum(dout * x_hat, axis=0)
dbeta = np.sum(dout, axis=0)
return dx, dgamma, dbet
参考资料
CS231N课程:https://cs231n.github.io/

