Global Textual Relation Embedding for Relational Understanding
Core Idea
全局的统计信息比局部的统计信息更加鲁棒。
在传统的关系抽取训练中,句子与句子之间是独立的,基于单句的局部特征训练模型,受到错误标签的影响比较大。本文提出了一种全局统计的思路,对每个句子,提取它文本中的关系表述(textual relation),并统计该 textual relation 在训练集中共现的 kb relation 的分布,这个分布可以用来作为 textual relation 的embedding 表示。
比如,对于上述两个textual relation,分别统计训练集中包含该textual relation的句子对应的label,可以得到texual relation在kbrelation上的分布如下:
可以看出,表述为born的句子可以被映射到place_of_birth上,虽然训练集中存在错误标签(place_of_death)的问题,但在全局统计的角度看,错误标签占比比较小。因此,全局共现信息可以有效地突出正确标签。
本文的思路可以类比 GloVE 对 word2vec 的改进。
Background
a representation between lexical (and phrasal) level and sentence level is missing. Many tasks require relational understanding of the entities mentioned in the text.
Definition Textual relation: the shortest path between two entities in the dependency parse tree of a sentence. (main bearer of relational information in text)
Definition distant supervision(远程监督): Distant Supervision 通过将知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
Distant Supervision 的提出主要基于以下假设:两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。例如,“Steve Jobs”, “Apple”在 Freebase 中存在 founder 的关系,则包含这两个实体的非结构文本“Steve Jobs was the co-founder and CEO of Apple and formerly Pixar.”可以作为一个训练正例来训练模型。这类数据构造方法的具体实现步骤是:
- 从知识库中抽取存在关系的实体对
- 从非结构化文本中抽取含有实体对的句子作为训练样例
Distant Supervision 的方法虽然从一定程度上减少了模型对人工标注数据的依赖,但该类方法也存在明显的缺点:
假设过于肯定,难免引入大量的噪声数据。如 “Steven Jobs passed away the daybefore Apple unveiled iPhone 4s in late 2011.”这句话中并没有表示出 Steven Jobs 与 Apple 之间存在 founder 的关系。
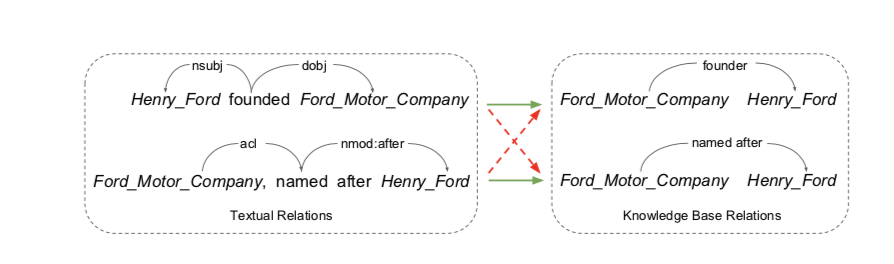
The wrong labeling problem of distant supervision. The Ford Motor Company is both founded by and named after Henry Ford. The KB relation founder and named after are thus both mapped to all of the sentences containing the entity pair, resulting in many wrong labels (red dashed arrows).
数据构造过程依赖于 NER 等 NLP 工具,中间过程出错会造成错误传播问题。针对这些问题,目前主要有四类方法:(1)在构造数据集过程中引入先验知识作为限制;(2)利用指称与指称间关系用图模型对数据样例打分,滤除置信度较低的句子;(3)利用多示例学习方法对测试包打标签;(4)采用 attention 机制对不同置信度的句子赋予不同的权值。
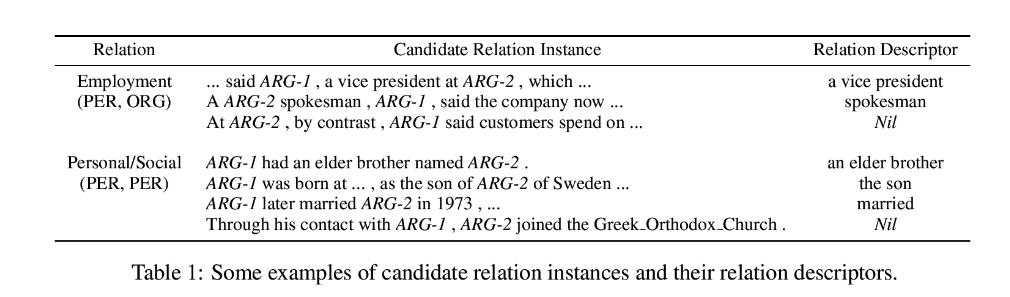
New York Times Dataset: NYT数据集是关于远程监督关系抽取任务的广泛使用的数据集。该数据集是通过将freebase中的关系与纽约时报(NYT)语料库对齐而生成的。纽约时报New York Times数据集包含150篇来自纽约时报的商业文章。抓取了从2009年11月到2010年1月纽约时报网站上的所有文章。在句子拆分和标记化之后,使用斯坦福NER标记器(URL:http://nlp.stanford.edu/ner/index.shtml )来标识PER和ORG从每个句子中的命名实体。对于包含多个标记的命名实体,我们将它们连接成单个标记。然后,我们将同一句子中出现的每一对(PER,ORG)实体作为单个候选关系实例,PER实体被视为ARG-1,ORG实体被视为ARG-2。
Contribute
- 通用的 relation embedding
- 创造了大规模的通过远程连接标注的数据集
- 在 relational understanding tasks(relation extraction(关系抽取) and knowledge base completion(知识库健全) ) 中,验证了我们方法的有效性。
- relation extraction : 使用我们的 embedding 增强 PCNN+ATT (Neural relation extraction with selective attention over instances)模型。
- Knowledge base completion : we replace the neural network in (Representing text for joint embedding of text and knowledge bases ) with our pre-trained embedding followed by a simple projection layer.
Proposal Model
(1) Global Co-Occurrence Statistics from Distant Supervision
Step one: map ClueWeb09 to Freebase Using FACC1 dataset
corpus : ClueWeb09
Knowledge base : Freebase
- Result : 5 billion entity mentions in ClueWeb09 and link them to Freebase entities. 155 million sentences containing at least two entity mentions.
- Note : 这里我们使用过滤器来剔除‘垃圾’关系。有4种删选策略(不展开)
Step two: use the Stanford Parser (Chen and Manning, 2014) with universal dependencies to extract textual relations (shortest dependency paths) between each pair of entity mentions
- 依赖树中找到两个实体之间的最短路径就是textual relation。
- Result : leading to 788 million relational triples (subject, textual relation, object), of which 451 million are unique.
Step three: calculate global co-occurrence statistics of textual and KB relations.
More specifically, for a relational triple with textual relation t, if with KB relation exists in the KB, then we count it as a co-occurrence of and .
Follows are a demonstration of r = ‘founder’ , ‘named_after’, t = ‘founded’, ‘named’.

Global co-occurrence statistics from our distant supervision dataset, which clearly distinguishes the two textual relations. (We found that in our dataset we surmount the difficult of mistaken distant supervisions.)
Step four : normalization & construct bipartite relation graph.
- each textual relation has a valid probability distribution over all the KB relations.
- one node set being the textual relations, the other node set being the KB relations, 权重就是先前计算的 normalize 之后的概率值。
(2) Embedding Training
Transformer as encoder.
The embedded textual relation token sequence is fed as input.
We project the output of the encoder to a vector z as the result embedding
Linear layer + softmax activation : the predict distribution of KB relation.
Loss measure the difference between the predict distribution and the ground truth set as global co-occurrence statistics value .
5% of the training data as validation set
Word embeddings are initialized with the GloVe
For the Transformer model, we use 6 layers and 6 attention heads for each layer.
Adam optimizer & 200 epochs & minimum validation loss for the result.
Summary : 作者首先通过全局的共同出现概率作为他们的标准训练信号(或者说label)通过 encoder 将包含 texitual relation t 的句子转换为embedding z,在训练过程中希望embedding z能够表征出 t 。
Expriments
参考资料
- distant supervision :https://www.dazhuanlan.com/2019/09/22/5d876517af55b/
- New York Times Dataset: https://www.dazhuanlan.com/2019/10/19/5daa084d5dd1f/
- Paper: https://sites.cs.ucsb.edu/~xyan/papers/acl19_gloreplus.pdf
- 别人的见解:https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/88096942

