(0) Preface
- 作者本人了解到 Transformer Bert 这些 2017-2018 年非常 hot 的模型已经有一段时间了。前一段时间在最终学习完成了CS231N课程之后,觉得自己已经达到了一个初级 Researcher 应有的对于深度学习模型的理解了,并且在上一学期也简单的熟悉了 Pytorch 框架基本的编程思维,决定再次挑战Transformer Implement。
- 除此之外,http://nlp.seas.harvard.edu/2018/04/03/attention.html 也给予了我很大帮助。
- Paper : Attention is All You Need
(1) Background
Transformer 的提出主要是为了解决:
- GRU/LSTM 网络可并行性差。
- 融合 sequence 中任意两位置的 input 所需要的操作随位置间隔增大而增大,这带来了长距离依赖关系难以传递问题。(直观的说,LSTM模型中相隔为 t 的两个词 , 间信息的传递需要进过t 次传递 , 同样的 CNN 中感受野也是类似,两个距离很远的像素之间的信息想要融合需要很多层 conv + pooling 操作)
(2) Model Architecture
Encoder-decoder structure : 解决序列转换问题的常用结构。
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.trg_embed = trg_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
return self.decode(self.encoder(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
Transformer 的结构整体上也是 Encoder-decoder 结构,显示如下:
![]()
(3) Encoder & Decoder 结构
Encoder
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
In Transformer, model employ a residual connection around each of the two sub-layers, followed by layer normalization (LN 本身就是针对序列问题设计的 Normalize 方法,具体可以见我的 Blog .
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# x.shape = [batch_size, sen_len, d_model]
mean = x.mean(axis=-1, keepdim=True)
std = x.std(axis=-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
这样,每一层的输出就是 。实际使用中,我们还在 Sublayer 之后添加了一个 Dropout 层。为了使残差网络能够正常工作,我们将 embedding layers, sub-layers, outputs 维数都规定为 512。
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
Transformer 每一层有两个 sublayer 构成。第一个 sublayer 是 multi-head self-attention,第二个是简单的前馈神经网络。
class EncoderLayer(nn.Module):
''' Encoder is made up of self-attn and feed forward (defined below)'''
def __init__(self, size, self_atten, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
Decoder
class Decoder(nn.Module):
"""Generic N layer decoder with masking"""
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
除了在 encoder 中使用过的两个子层之外,decoder 使用了第三个 sub-layer(在encoder stack的 output 上进行 multi-head attention.)和encoder相同的,使用残差网络链接每一个子层,然后使用layer normalization。
class DecoderLayer(nn.Module):
"""Decoder is made of self-attn, src-attn, and feed forward."""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x , tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
与 encoder 不同的是,为了防止 decode 过程中看到后续的信息,decoder 中 mask 需要保证预测第 i 位置的词时仅依赖于已知的在 i 之前产生的 outputs 信息。
def subsequent_mask(size):
"""Mask out subseqent position"""
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
![]()
图中蓝色表示能看到,第 行表示 能看到的范围。(比如第三行蓝色有\
(4) Attention
“Scaled Dot-Product Attention” :Scaled 表示将点积结果进行了放缩。
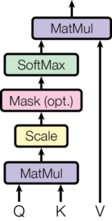
实际上,我们并行的序列化计算一系列 queries,拼接他们成 矩阵,同样的 , 矩阵也由 key, value值拼接而成。
def attention(query, key, value, mask=None, dropout=None):
# query.size = key.size = value.size = [batch_size, sen_len, dk]
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
score = scores.masked_fill(mask==0, 1e-9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
Scale : 原理直接处理的话各项的差值较大,softmax 的梯度趋近于零,不利于模型收敛。假设q,k每一项都符合(0,1)正态分布,则 应服从 的正太分布。故此除以 使之标准化。
不仅如此,我们通常不仅仅使用单一 attention 机制,而是使用multi-head 注意力机制。
![]()
多头注意力机制提供了模型将输入映射到不同的子空间分别进行 attention 的能力
其中 将输入 映射到第 个 head 的 上
其中 将输入 映射到第 个 head 的 上
其中 将输入 映射到第 个 head 的 上
为了维持模型的计算复杂度我们减小了每一个 head 对应的输出维度, 。
其中 将所有head输出拼接的结果进行映射整合。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"""Take in model size and number of heads"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0, "wrong d_model or h"
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""Implement of Figure 2.
query.size = key.size = value.size = [batch_size, sen_len, d_model]
"""
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
这里比较 trick 的技巧是用一个 的 Linear 层直接统一求所有的(8 个)head的Q,K,V。
然后,利用.transpose() 和 .view() 操作对每一个 head 进行 attention 然后合并。
(5) Applications of Attention in our Model
The Transformer uses multi-head attention in three different ways:
1) “encoder-decoder attention”: queries from previous decoder layer, and the memory keys and values come from the output of the encoder. 这个 attention 使 decoder 中每一个位置都能顾及所有输入序列的位置
2) encoder self-attention layers: Q, K, V 都来自 previous encoder layer。
3) decoder self-attention layers: Q, K, V 都来自 previous decoder layer。& masking out (setting to -inf) all value in the input of the softmax which correspond to illegal connections.
(6) Position-wise Feed-Forward Networks
encoder & decoder 包含全连接子层(input.size =[bat_size, sen_len, dmodel]) 对每个位置进行相同的变换。
其中,中间层维度 。
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
(7) Embeddings and Softmax
Embedding : (Input & output) tokens -> vectors of dimension
linear Transformation & softmax : convert decoder output -> next-token probabilities.
In Embedding layers, we multiply those weights by
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
(8) Positional Encoding
其中 pos 表示 单词位置 position, i 表示 对应的维度 dimension.
模型采用 0.1 的 dropout 在 encoder 和 decoder 的(embeddings + position encodings)上。
class PositionalEncoding(nn.Module):
"""Implement the PE function"""
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# compute the positional encodings once in log space
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(postion * div_term)
pe[:, 1::2] = torch.cos(postion * div_term)
pe = pe.unsqueeze(0)
# pe.size = [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
(9) Full Model
这里我们定义一个函数输入所有超参数,产生一个完整的模型。
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""helper: Construct a model from hyperparameters."""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
Generator(d_model, tgt_vocab)
)
# this was important from their code.
# Initialize parameters with Glorot / fan_avg
for p in model.parameters():
if p.dim() > 1: # filter out bias items.
nn.init.xavier_uniform(p)
return model
# Test.
tmp_model = make_model(10, 10, 2)
(10) Training
Interlude for tools needed to train a standard encoder decoder model. First we define a batch object that holds object that holds thhe src & target sentences for training, as well as constructing masks
(10.1) Batches and Masking
class Batch:
'''Object for holding a batch of data with mask during training'''
def __init__(self, src, trg=None, pad=0):
# src : token sequence [batch_size, sen_len]
# trg : token sequence [batch_size, sen_len']
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
'''Create a mask to hide padding and future words.'''
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
(10.2) Training Loop
def run_epoch(data_iter, model, loss_compute):
'''Standard Training and Logging Function'''
# Train model for one epoch.
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg, batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print(f"Epoch Step: {i}, Loss: {loss / batch.ntokens}, Tokens per Sec: {tokens / elapsed}")
start = time.time()
tokens = 0
return total_loss / total_tokens
(10.3) Training Data and Batching
Dataset: standard WMT 2014 English-German dataset (4.5million sentences pairs). Sentences were encoded using byte-pair encoding, which has a shared source-target vocabulary of about 37000 tokens.
注意:在将sentence pair 组成 bundle 的过程中,应尽量将长度相似的句子放入一个 bundle。
使用 torchtext 来构造 batching. Here we create batches in a torch text function that ensures our batch size padded to the maximum batchsize does not surpass a threshold.
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
'''Keep augmenting batch and calculate total nubmer of tokens + padding.'''
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
(11) Optimizer
采用 Adam 优化器 , , , 学习率采用 warmup 策略,先逐渐上升,然后逐渐下降。 ,这里采用的warmup_steps = 4000.
class NoamOpt:
'''Optim wrapper htat implements rate.'''
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
'''Update parameters and rate'''
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step=None):
'''Implement lr above'''
if step is None:
step = self._step
return self.factor * (self.model_size ** (-0.5) * min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0,
betas=(0.9, 0.98), eps=1e-9))
下图展示了使用这种 warmup 的调整 lr 方法学习率随 epoch 的变化
# Three settings of the lrate hyperparameters.
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
![]()
(12) Regularization
(12.1) Label Smoothing
During training, we employed label smoothing of value ϵls=0.1ϵls=0.1 (cite). This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
We implement label smoothing using the KL div loss. Instead of using a one-hot target distribution, we create a distribution that has confidence of the correct word and the rest of the smoothing mass distributed throughout the vocabulary.
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
(之后会详细的分析一下Label Smoothing 的原理和作用)。
(13) A First Example
我们首先尝试一个简单的 ‘copy-task’, 即训练集的 label = input,希望model 能够对于任意输入输出其 token 的 copy。
(13.1) Synthetic Data
def data_gen(V, batch, nbatches):
'''Generate random data for a src-tgt copy task.'''
for i in range(nbatches):
data = torch.from_numpy(np.random.randint(1, V,
size=(batch,10)))
data[:, 0] = 1
src = Variable(data, requires_grad=False)
tgt = Variable(data, requires_grad=False)
yield(Batch(src, tgt, 0))
(13.2) Loss Computation
class SimpleLossCompute:
'''A simple loss compute and train function.'''
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion(x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)) / norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.data.item() * norm
(13.3) Greedy Decoding
V = 11 # 10 + 1(padding)
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400, torch.optim.Adam(model.parameters(), lr=0, betas=(0.9,0.98), eps=1e-9))
for epoch in range(10):
model.train()
run_epoch(data_gen(V, 30, 20), model, SimpleLossCompute(model.generator, criterion, model_opt))
model.eval()
print(run_epoch(data_gen(V, 30, 5), model, SimpleLossCompute(model.generator, criterion, None)))
![]()
使用Greedy Search decoding 来对输入进行预测。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(memory, src_mask, Variable(ys), Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data.item()
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
model.eval()
src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]))
src_mask = Variable(torch.ones(1, 1, 10))
print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1))
Summary
- 这是我第一次完整的阅读 Transformer 论文的源代码,感觉一方面对 Transformer 的一些内部原理又了更加清晰的把握,另一方面也学到了很多工程中常用的tricks:比如优化器的封装,初始化的描述等等。
- 感觉自己之前 还是读别人代码读的比较少,一直按照自己的 “初学者” 的模式,写模型,收到很大的框架的局限性。通过本次阅读,了解了不少之前没有用过,见过的模型构架。受益良多。
(Appendixes) Reference
- Transformer tutorial: https://zhuanlan.zhihu.com/p/84157931
- Havard NLP Group: http://nlp.seas.harvard.edu/2018/04/03/attention.html

