Paper Reading
Date: 2020/4/10
Multimodal BiTransformers
Multimodal bitransformer model as follows:
![]()
Image Encoder
Within the multimodal bitransformer architecture, however, we can handle arbitrary lengths and are not committed to a partic- ular number of inputs. Thus, we generalize the final pool- ing layer to yield not one single output vector, but N separate image embeddings, unlike in a regular convolutional neural network.
In this case we use a ResNet-152 (He et al. 2016) with average pooling over K × M grids in the image, yielding N = KM output vectors of 2048 dimensions each, for every image.
相当于对于图片中选择 个区域进行 nn.AdaptiveAvgPool2d 每个区域都对应生成一个2048 dim的vector。
输入图像经过 torchvision.transfroms 处理形成固定大小224x224的 Tensor 作为输入。
Multimodal Transformer Input Layer
Token seq (batch_size, seq_len)->
Step one : 使用 bidirectional transformer architecture 以及pre-trained BERT initialize. (batch_size, seq_len, D) 得到text 的 token embedding 并于position embedding 和 segment embedding 做element-wise sum 求得最终的 contextual embedding (batch_size, seq_len, D) .
Step two : 使用 对图片n 作 linear 变化使之变成 维
其中, 是第 个区域的image encoder 输出结果 (batch-size, 2048)
对于1个text + 1个 image 的task,我们将text的segment设置为一个特定的值,将image的segment设定为另一个值(例子中为0/1)。使用下标从0开始的seq为text和image分别进行位置编码。这种结构可以推广到任意数量的图片和text结构中(V-SNLI task)。
Since pretrained BERT itself has only two segment embeddings, in those cases we initialize additional segment embeddings as where is a segment embedding for . (这块有点没懂,之前没见过bert中的segment embedding,而且这样 是不是 segment embedding 是不是都相似了呢 )。 文中还提到他们的adv在于这种对于text/image数量的通用性。
Classification
这一块和之前看到的Bert的在垃圾邮件分类中的介绍就比较像了,都是用first output of the final layer 输出接到 上进行分类。multiclass 和 multilabel 使用的方法略有区别。
Pretrain
imag encoder : torchvision.models.resnet152(pretrained=True) 估计是只用layer1-layer4 吧(我记得conv1 好像目的是将图片变成224x224?后面的fc应该是用不上了)
text encoder : Bert 12 layer 768-dim。
Fine-tuning and Multimodal Optimization
Bert: it is common to fine- tune BERT in its entirety, and not to transfer the encoder while keeping its parameters fixed (这一部分有点没懂,还没咋用过BERT)
ResNet : unfreezing the conv network during later stages.
交替冻结image和text encoder (ResNet, BERT)
we freeze and unfreeze the image and text encoding components at different stages, which we treat as a hyperparameter.
For example, if we first learn to map image embeddings to an appropriate subspace of the text encoder’s input space, we may expect the network to make more use of visual information than it otherwise would. In other words, since the text modality is likely to dominate, we want to give the visual modality a chance. We experiment with different settings. (就是说在学习 的时候freeze BERT 参数了吗?没看懂)
Approach
Evaluation
MM-IMDB / FOOD101
为显示我们的模型对于不同的text/image 数目的泛化能力还在 V-SNLI : (premise, hypothesis, image) triplets 进行了测试。
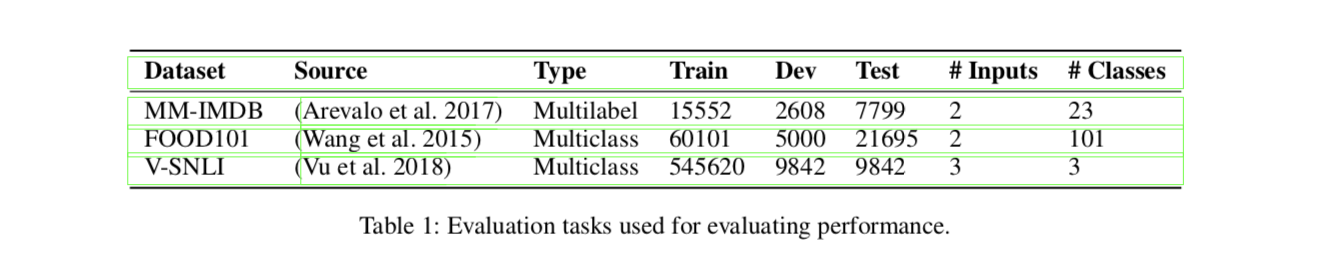

V-SNLI 数据集中Premise是Flickr30k的caption任务中的caption,Hypothesis是Turkers标注的。原始图片加Premise & Hypothesis构成了这个任务的三个输入。
Baselines
In all cases we use a single layer classifier. Baseline are shown as follows:
Unimodal baseline
Bag of words (Bow) We sum 300-dimensional GloVe embeddings for all words in the text, ignoring the visual features, and feed it to the classifier.
Text-only BERT (Bert) We take the first output of the final layer of a pre-trained base-uncased BERT model, and feed it to the classifier.
Image-only (Img) We take a standard pre-trained ResNet-152 with a single average pooling operation as output, yielding a 2048-dimensional vector for each image, and classify it in the same way as the other systems.
concatenating multimodal features as direct features for the classifier.
- Concat Bow + Img (ConcatBow) We concatenate the outputs of the Bow and the Img baselines. Concatenation is often used as a strong baseline in multimodal methods. In this case, the input to the classifier is 2048+300- dimensions.
- Concat BERT + Img (ConcatBert) We concatenate the outputs of the Bert and the Img baselines. In this case, the input to the classifier is 2048+768-dimensions. This is a highly competitive baseline, since it combines the best en- coder for each modality such that the classifier has direct access to the encoder outputs.
Making the Problem Harder
hard test sets created specifically for examining multimodal performance (i.e., where unimodal performance fails).
In the hard ground-truth test set, we take the examples where the Bow and Img classifier predictions are most different from the ground truth classes in the test set, i.e. examples that maximize , where I and T are the image and textual information respectively, a is the predicted answer and t is the correct answer.
In the hard disagreement test set alternative, we do not compare to the ground truth, but instead look at cases where the Bow and Img classifiers disagree with each other the most. We take the top 10% of the most-different examples as the hard cases in the new test sets.
Implementation Details
Learning rate : {1e-4, 5e-5}
Early stop : on validation accuracy for the multiclass datasets, and Micro-F1 for the multilabel dataset.
Epochs: & Number of Image Embedding: ( hyper parameters)
Optimizer: BertAdam & Adam
Since not all datasets are balanced, we weight the class labels by their inverse frequency (这一点有点没懂啥叫weight the class labels)
Results
mean performance over 5 runs with random seeds together with the standard deviation.
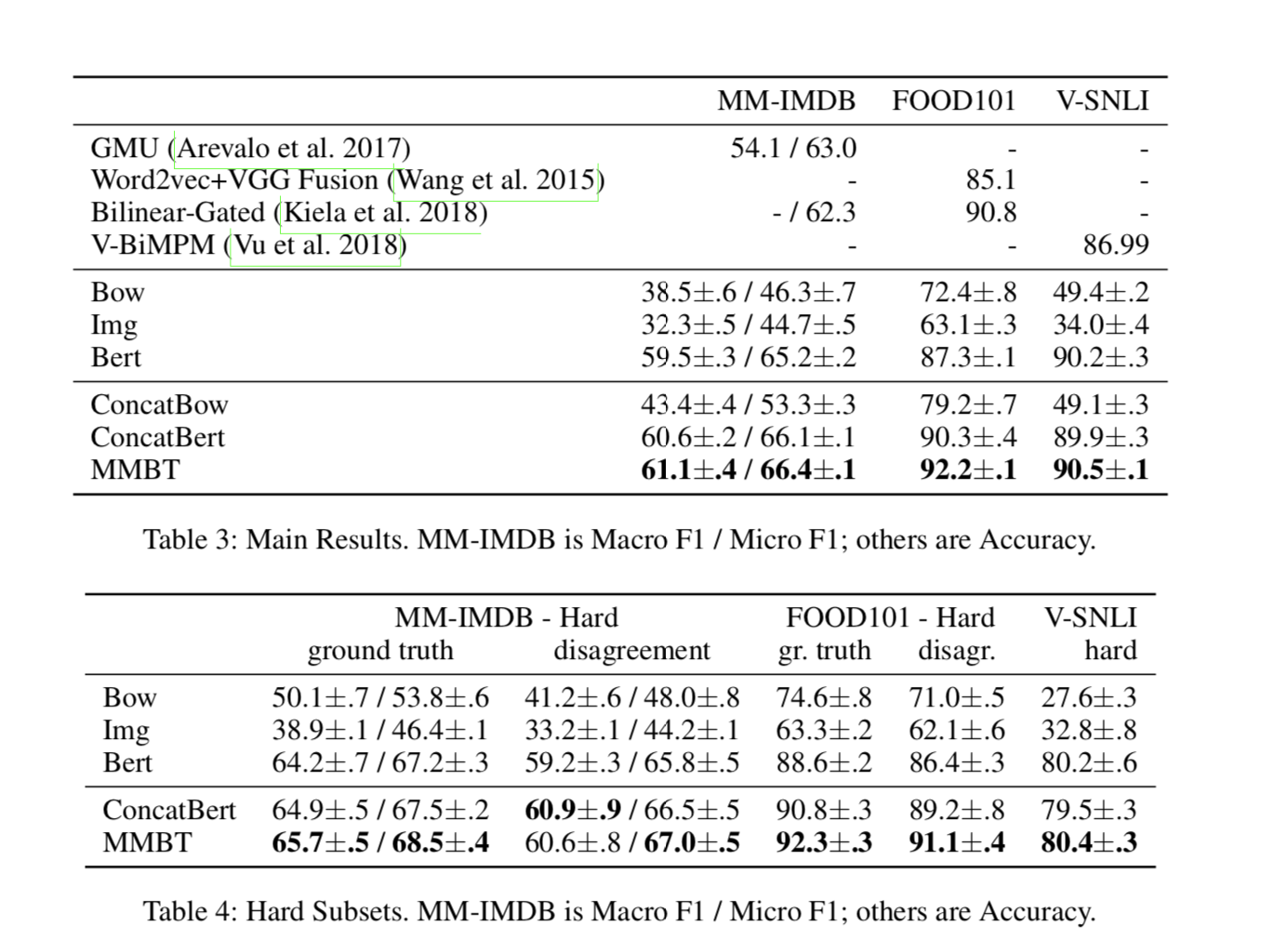
Bilinear-gated model 为啥 2048x768x101没太懂,(2048x768怎么来的?2048 是img_feature, 768 text_feature 为啥相乘) meaning that one of the two input modalities is sigmoided and then gates over the other input bilinearly, i.e. by taking an outer product这句话没太懂。后面的result说明没细看了。
Analysis
主要看的是Freezing Strategy
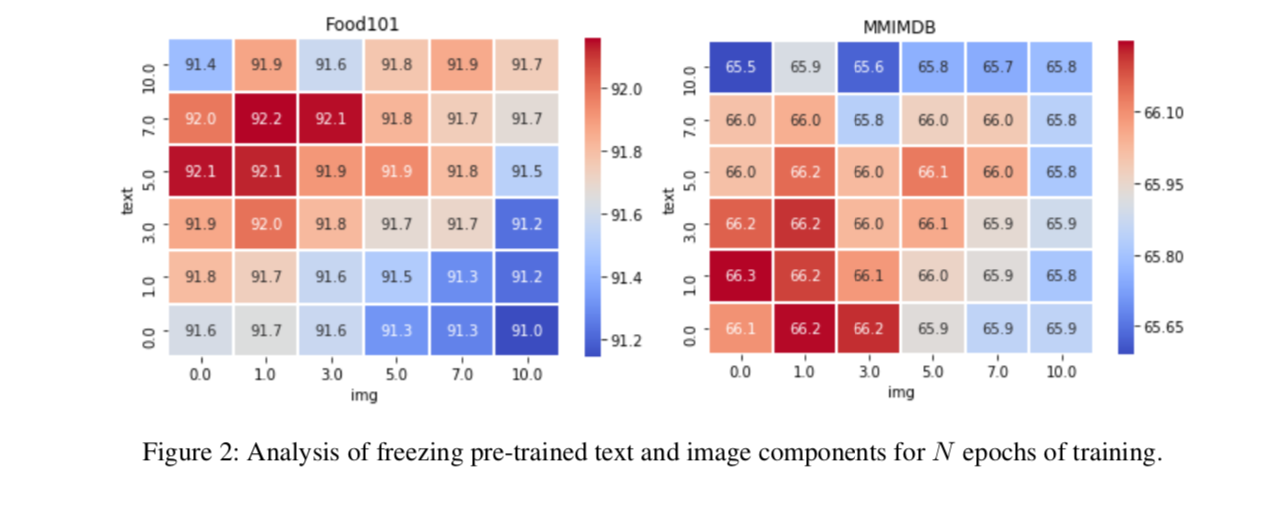
It is useful to first learn to put the components together, then unfreeze the image encoder, and only after that unfreeze the pre-trained bitransformer.
Reference
Original Paper : Supervised Multimodal Bitransformers for Classifying Images and Text

