Summary of Word2vec
Preface
之前,在面试阿里的时候,提到了Embedding的问题,面试官问我了解哪些基本的embedding,我提到了word2vec,然后面试官就追问了word2vec的原理,当时没有准备,答得比较凌乱,现结合其他人的 blog 总结 Word2vec 原理回答的主要思路。
本文总结的时候参考了一下文章:
本文图片出处original cs224n,本文图片来自 知乎
(1)概览
核心思想:预测每个单词与其上下文之间的关系
两种不同的算法:
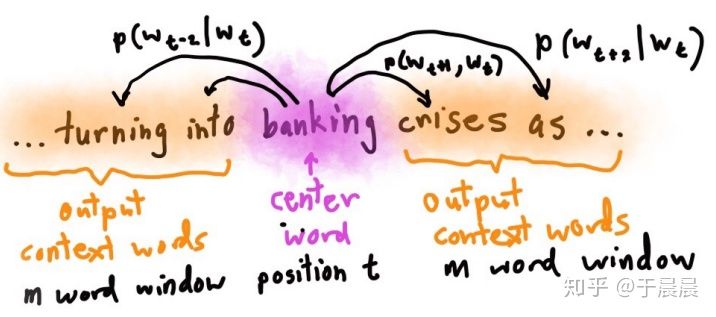
- Skip-grams (SG) : 给定中心单词,预测中心词的上下文单词(位置独立)
- Continuous Bag of Words (CBOW) : 从给定的上下文单词,预测中心词。
两种训练方法:
- Hierarchical softmax
- Negative sampling
(2) Skip-grams 算法
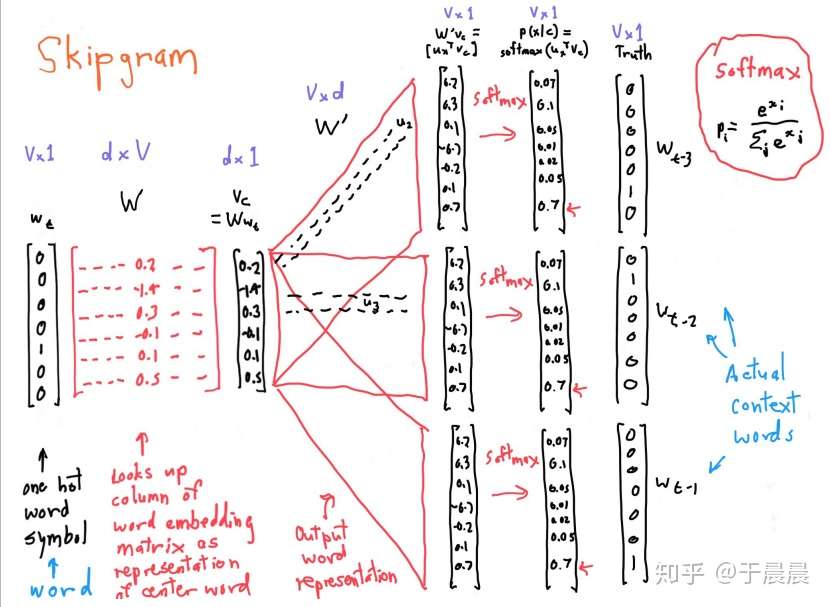
模型说明:
模型预测给定单词 为中心词,该词“半径”为 的窗口中的单词,即给定中心词 最大化上下文单词的概率。即最大化如下目标函数:
等价于最小化negetive log likelihood:
其中,我们使用如下公式计算 。
注意的是,这里对于每个单词来说对应了两个不同的词向量, (分别作为外部和中心词的向量表示)。通过softmax函数,使用中心词 获取输出单词 的概率分布。
skip-grams 的框架
下图展示了 skip-grams 的框架 (使用softmax而不是Hierarchical softmax/Negative sampling)