Multi-modality Latent Interaction Network for Visual Question Answering
Multi-modality Latent Interaction Network
MLIN consists a series of stacking Multi-modality Latent modules. (The inputs and outputs of the MLI module has the same dim)
MLI Aims : summarize input visual-region and question-word information into a small number of latent summarization vectors.
In the last stage, we conduct elementwise multiplication between the average features of visual regions and question words to predict the final answer.
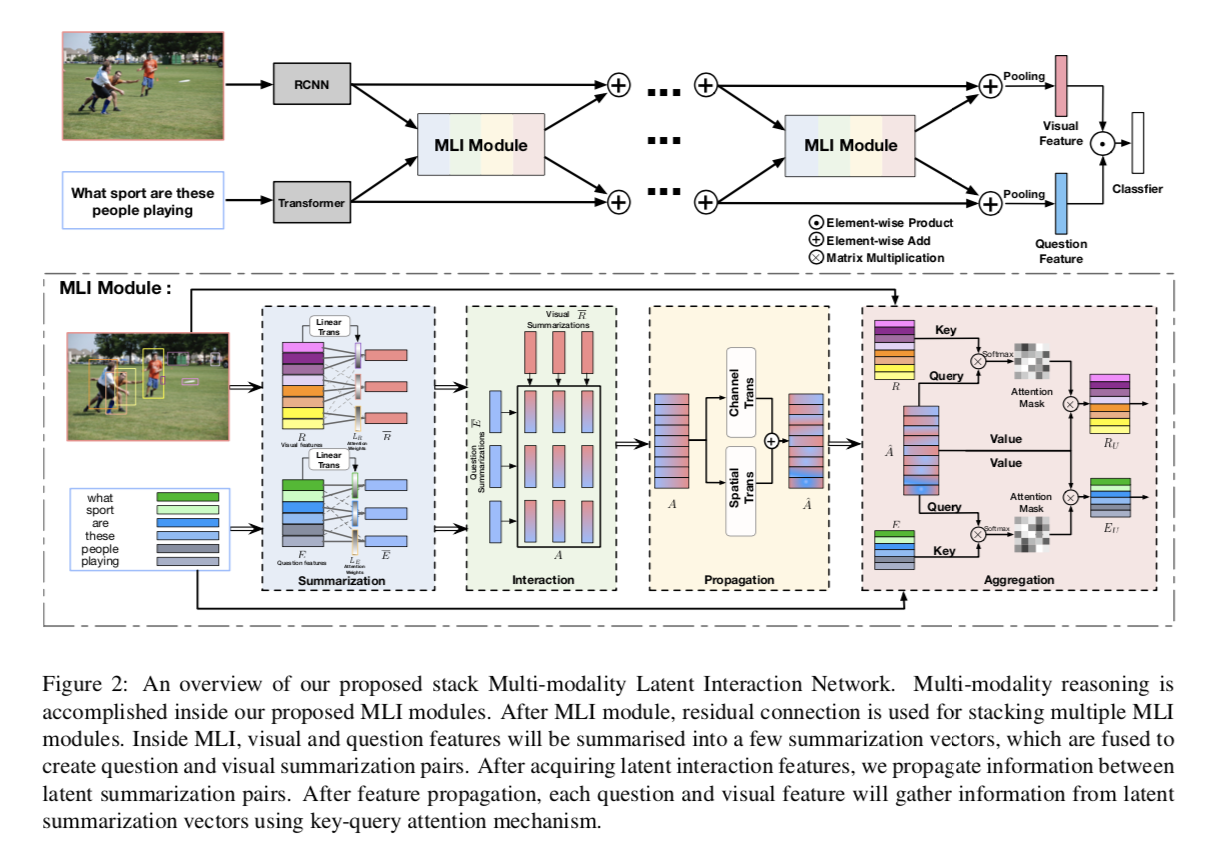
3.1 Question and Visual Feature Encoding

3.2 Modaliity Summarizations in MLI Module

3.3 Relational Learning on Multi-modality Latent Summarizations
Relational Latent Summarizations
input : [k, 512]
Output: Relational Latent Summarizations [k, k, 512]
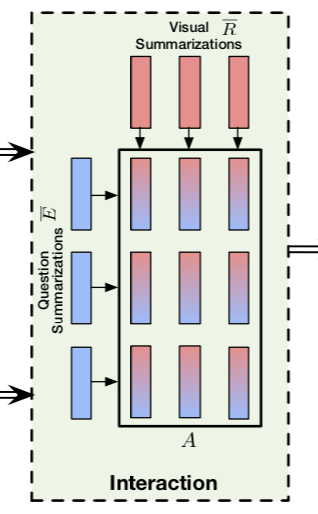

Relational Modeling and Propagation

Feature Aggregation

前四步给出了模型update region/word feature的方法:首先利用R/E的原始输入分别聚合为k个512d的region/word特征,然后顺序构造A矩阵并使用attention的机制利用每一个region/word 特征在A矩阵上的关注程度聚合信息,最后利用了Resnet的思想,学习变化而不是映射本身.
可以看到MLI模型的输入和输出维度相同。我们可以使用多层MLI来细化视觉和单词特征。
最后,我们对视觉区域特征和单词特征进行平均池化,并对池化后的两种特征进行元素乘操作,最后,采用具有SoftMax非线性函数的线性分类器进行答案预测。
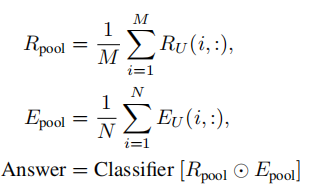
整个系统使用交叉熵损失函数以端到端的方式训练。

