Paper:Words Can Shift: Dynamically Adjusting Word Representations Using Nonverbal Behaviors
Link:https://arxiv.org/abs/1811.09362
核心思路
- 通过 shifting word embedding 的方式将非文本信息融合到文本 embedding 中。
- 关注细粒度的非语言信息(对于每一个单词对应时间片的video/audio信息提取)
- 主要考虑到对应于每一个词时间片(video/audio都是一个sequence数据)
- 通过可视化 word embedding 的 shift 的变化可以了解非文本信息的作用。(用于模型可解释性的研究)
模型结构
- 模型结构图已经非常清晰了(只有如何做注意力机制需要稍作补充即可)
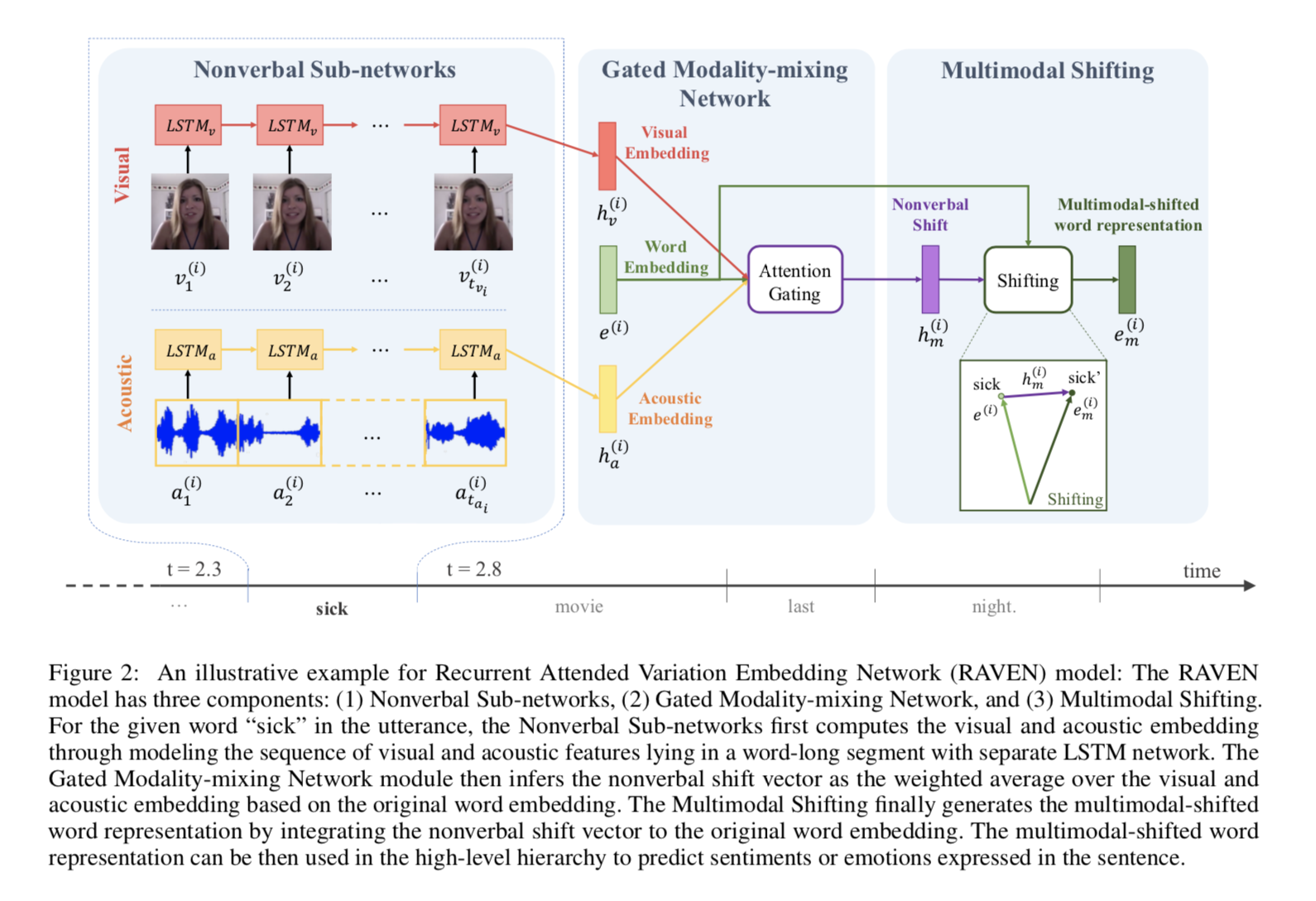
模型的注意力计算方法:
首先计算 visual / audio 的 influence 大小(scalar)
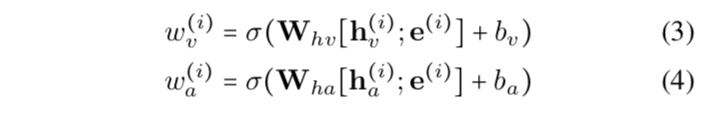
然后求 Nonverbal Shift vector:
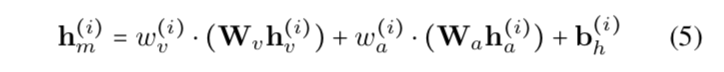
关于模型的 shift 部分使用和 Integrating Multimodal Information in Large Pretrained Transformers 工作相同的 shift 的 trick :
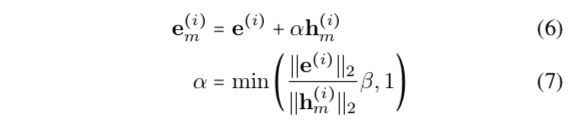
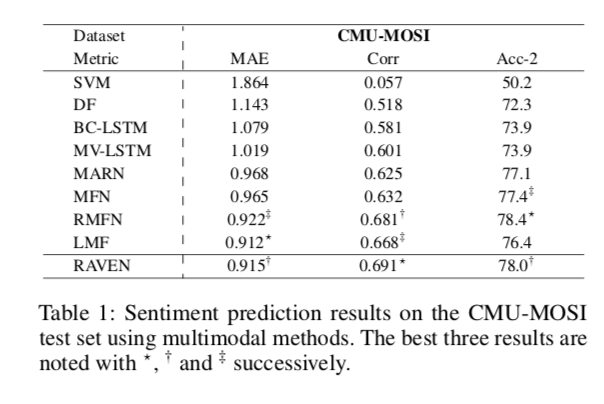
模型效果
可解释性工作
visualize the distribution of shifted word representations that belong to the same word. (使用PCA 进行embedding 降维进行可视化,绘制了正例和负例的Gaussian contour,并绘制了中心点,并画出了总体(正例+负例)质心 到正例质心、负例质心的路径)
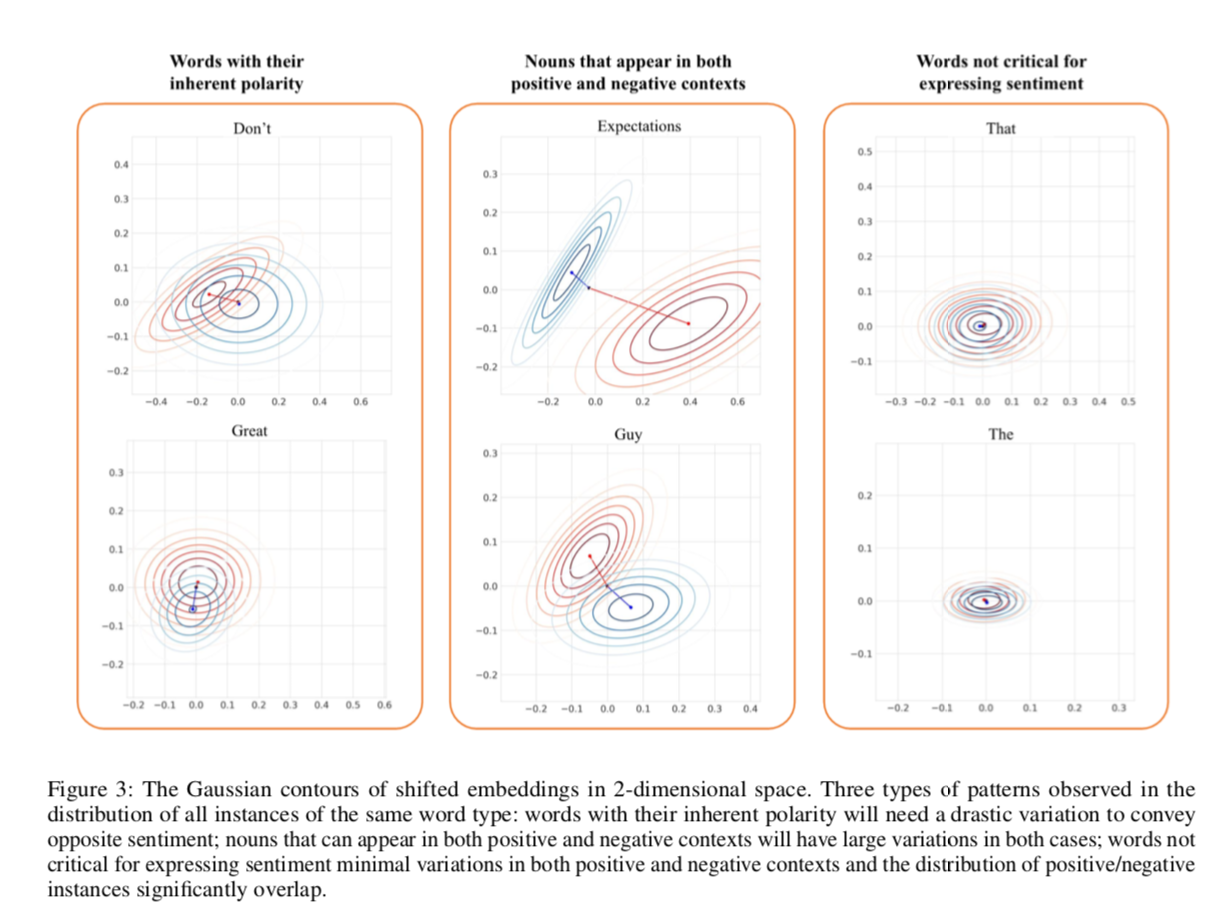 -
- 对于不同的词 shift 情况可以分成 3 类:
- For words with their inherent polarity
- 对于含有 sentiment bias 的词:与本意相同的 contour 质心变化很小,与本意不同的 contour 质心变化很大
- 单词“ great”的整体质心非常接近于其正质心,而其负质心与整体质心和正质心都相距甚远。
- For nouns that appear in both positive and negative contexts
- 尽管此类名词通常指的是情感上没有明显极性的实体,但我们的模型会根据附带的多峰语境学习“极化”这些表示。
- 例如,名词“ guy”经常用于称呼好演员和坏演员,并且RAVEN能够相应地在单词嵌入空间中将它们朝两个不同的方向移动。
- For words that are not critical in conveying sentiment
- 几乎重合
- For words with their inherent polarity
我的观点
这篇文章在模型上本质创新在于
video/audio 做了 fine-grained 的 lstm 以外
采用了 shifting 的思想进行多模态融合,讨论了模型的可解释性。
感觉上思路比较平淡,这种 shifting 的思路在 Integrating Multimodal Information in Large Pretrained Transformers 论文中使用过,不知道那篇文章提出比较早,那篇文章的效果也是优于这篇工作
个人感觉这篇工作是在对于多模态融合过程的初步探索吧,因为 shifting 这个过程非常类似于在计算机视觉中对 CNN 浅层通过对于权重矩阵进行可视化,进行模型可解释性的工作。在Integrating Multimodal Information in Large Pretrained Transformers 中也用了 shift 但是由于是在非第一层做的 shifting 所以谁也说不清是到底完成了什么工作qaq。shifting本身确实是对于可解释性的一种尝试。
这给了我一些启发,可以参考在 CV 工作中的一些常用的可视化技术进行模型可解释性的分析。

