Multimodal Dataset
Summary from Paper : Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph
Previous Dataset Shortcoming
- Diversity in the training samples:
- Previously proposed datasets for multimodal language are generally small in size due to difficulties associated with data acquisition and costs of annotations.
- The diversity in training samples is crucial for comprehensive multimodal language studies due to the complex- ity of the underlying distribution.
- Variety in the topics:
- Models trained on only few topics gener- alize poorly as language and nonverbal behaviors tend to change based on the impression of the topic on speakers’ internal mental state
- Diversity of speakers:
- speaking styles are highly idiosyncratic.
- Variety in annotations:
- Having multiple labels to predict allows for studying the relations between labels.
- Another positive aspect of having variety of labels is allowing for multi-task learning which has shown excellent performance in past research.
Dataset Comparision
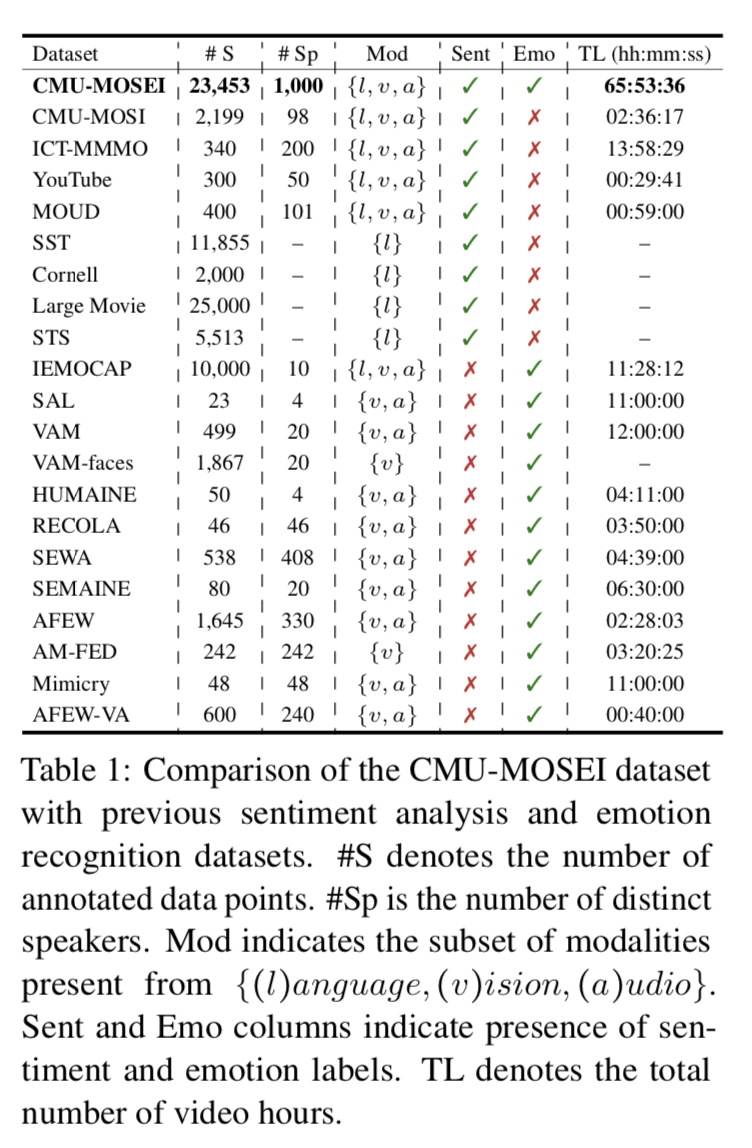
CMU-MOSI 2016
- 2199 opinion video clips each annotated with sentiment in the range [-3,3]
(*) CMU-MOSEI (this paper)
- contains 23,453 annotated video segments from 1,000 distinct speakers and 250 topics.
- contains manual transcription aligned with audio to phoneme level.
ICT-MMMO 2013
- consist online social review videos annotated at the video level for sentiment.
YouTube 2011
- contains video form YouTube that span a wide range of product reviews and opinion videos.
MOUD 2013
- consists of product review videos in Spanish. Each video consists of multiple segments labeled to display positive, negative or neutral sentiment.
IEMO-CAP 2008
- consists of 151 videos of recorded dialogues, with 2 speakers per session for a total of 302 videos across the dataset.
- each segment 9 emotions as well as valence arousal and dominance.
Common Baseline
- MFN : (Memory Fusion Network 2018)
- MARN: (Multi-attention Recurrent Network 2018b)
- TFN: (Tensor Fusion Network 2017)
- MV-LSTM(Multi-View LSTM 2016)
- EF-LSTM(Early Fusion LSTM 2013)

