多模态论文感情分类篇(VistaNet)
写在前面:本计划好直接从 code 入手直接看模型实现,但是一看 source code:tensorflow,奈何 PyTorch 党看 tensorflow 过于不适,只能先从 paper 读起,也算是没能走到捷径。
Paper 发表在 AAAI 2019 上,实现的最后一次提交也是 1 year 以前力,谈不上很新鲜,但是至少提供了处理数据集的代码和在数据集上测试的代码。有可以借鉴的地方。
(1)论文阅读 模型综述
核心思想:VistaNet relies on visual information as alignment for pointing out the important sentences of a document using attention.
主要贡献:
- the first to incorporate images as attention for review-based sentiment analysis.
- VistaNet Model
- conduct comprehensive experiments on Yelp restaurant reviews from five major US cities against comparable baselines.
问题重述:给定一个文档集合 $C$, 对于每一个 $c \in C$ 的文档,包含:
- textual 部分: $L$ 个句子序列 $s_i, i\in [1, L]$, 每个句子 $s_i$ 可以表示为由 $T$ 个单词的序列,即 $s_i = \{w_{i,1},\cdots,w_{i,T}\}$
- visual 部分:有 $M$ 张照片组成 记为 $a_j \in \{a_1, a_2, \cdots, a_M\}$
- Sentiment label : 一个情感标签
需要注意的是 :每个文档包含的句子个数和图片数目可能不相同,我们目标是通过textual+visual 部分学习分类器预测未见的文档的Sentiment label。
(1.1)Visual Aspect Attention Network
- Overall Structure: hierarchical three-layered architecture
- The bottom layer is the word encoding layer with soft attention, where we transform word representations (Glove) into a sentence representation.
- The middle layer is the sentence encoding layer where we transform the sen- tence representations into a document-level representation, with the help of the visual aspect attention.
- The top layer is the classification layer to assign the document a sentiment label.
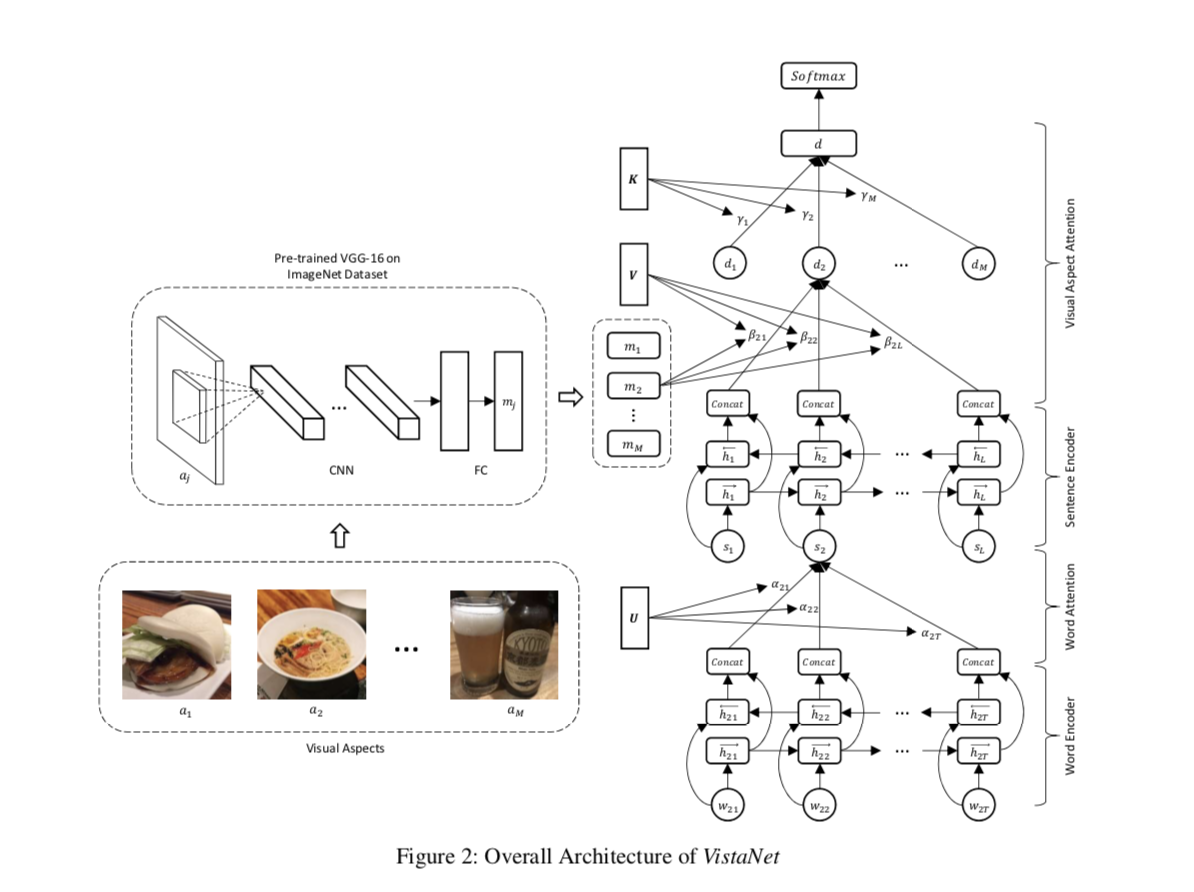
Word Encoder with Soft Attention
首先是使用了 Glove 预训练词向量,将 token seq ($w_{i,1}, \cdots, w_{i,T} $) 转化为词向量序列 $(x_{i,1}, \cdots, x_{i, T})$。
然后使用 Bi-RNN (GRU cell) 来获得结合上下文的词向量编码 $h_{i,t} = BiRNN(x_{i,t})$.
接下来,模型使用软注意力机制 (soft attention mechanism),为不同的单词对于句子语义的贡献进行加权, 权重计算方法如下:($u_{i,t}$ 可理解为计算贡献分数,$\alpha_{i,t}$ 归一化分数,句子级别表示 $s_i$ 为各个结合上下文单词表示的加权平均)
其中,$U$ 是上下文矩阵,是模型学习的参数之一(随机初始化)
Sentence Encoder with Visual Aspect Attention
visual aspect attention :a soft attention mechanism using visual information to improve the quality of learned document representation.
首先仍然使用 Bi-RNN 处理底层得到的句子向量表示,得到包含上下文信息的句子表示 $h_i = BiRNN(s_i)$ 。
使用预训练的 VGG-16 得到每张图片 $a_j$ 的表示 $m_j$ (用 VGG-16 的 fc7 层结果作为$m_j\in R^{4096}$)
对于每个不同的图像 $m_j$ 使用 attention 的方法计算每个句子 $h_i$ 的权重
- 首先将 $m_j$ $h_i$ 进行线性变换到 attention space 本质:1. 使他们有相同的 dim 2. 进行非线性变化提升模型表示能力
- 进行 attention 处理,并归一化
这里作者强调了再计算 $v_{j,i}$ 中使用哈达码乘积 + sum 操作的必要性:Without the element-wise multiplication, and with only summation, the effects of the visual part would have been cleared out by the softmax function when calculating attention weight $\beta_{j,i}$. Without the summation, and with only the element- wise multiplication, the effects of the text part would have been significantly weakened because of the sparsity of the visual part.
加权聚合句子级别信息得到文档的表示:
对于每一个文档,我们对于其中的每个图片使用上述方法得到 a set of aspect- specific document representations $d_j ,j\in[1,M]$
将 set of aspect- specific document representations 聚合成最终的文档表示(认为不同的图片的重要性不同,需要学习计算图片权重的方法,在使用一次加权平均的方式的到最终文档表示 $d$)
Sentiment Classification
最后在模型的最上层,利用上面的到的文档表示 $d$ 我们使用 softmax-based sentiment classifier, 生成概率分布。
模型是使用最小化交叉熵函数的方法进行优化
Summary :
- 本篇文章其实就是使用了 2016年 提出的 多层注意力模型(Hierarchical Attention Networks for Document Classification(NAACL2016))原文章是在文档分类问题中提出的。本文本质上就是对于这种方法在多模态问题上的一个改进,使用图片信息进行soft attention。
- 对于多模态问题,核心问题在于不同模态信息的 fusion 可以考虑从传统的 nlp/cv 模型中“借鉴”思想。以本文为例,核心是 document 中文档信息与图片信息的提取+分类。我们可以从nlp中的文档信息提取的工作中的到灵感。
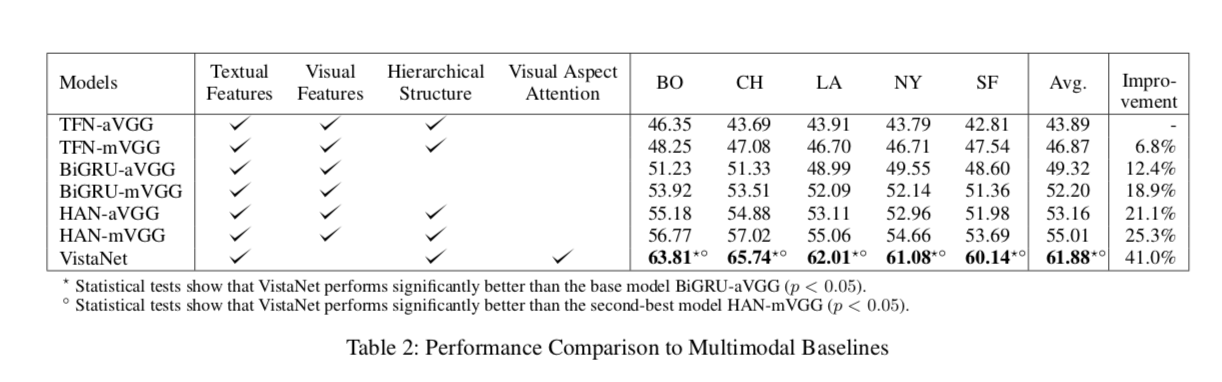
(2)模型实现 效果总结
数据集:Yelp 数据集(http://static.preferred.ai/vista-net/data.zip)
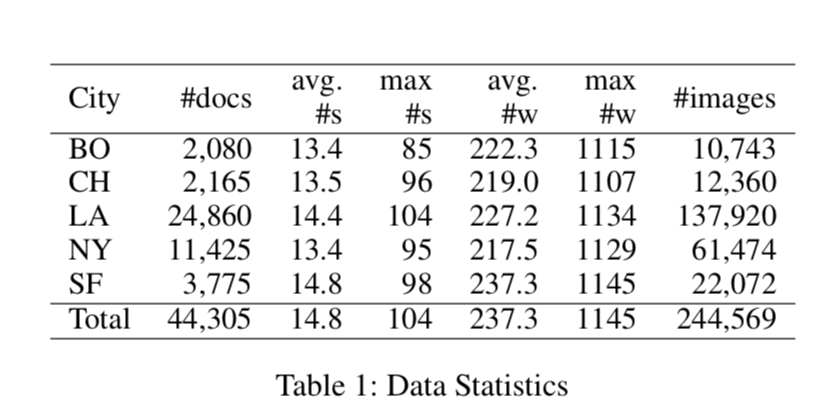
模型效果:
(3)Todo Next
- 首先,下一步是阅读源代码的实现,找到其实现的核心部分&数据处理部分代码进行学习。
- 然后,我们希望能够使用 pytorch 对于原本的 tensorflow 实现进行复现。(Ps.可能要等一波考完 junior 的期末考试力)
(4)参考文献
论文原文链接:https://drive.google.com/file/d/12d8SZiNeKFgIGmO5VHSrZV2jkgwYZpNp/edit(需要梯子)

